

Ars Tecnica
Giovedì, i ricercatori Microsoft hanno annunciato un nuovo modello di intelligenza artificiale text-to-speech chiamato Valle Può imitare da vicino la voce di una persona quando viene fornito un campione audio di tre secondi. Una volta che ha appreso un suono specifico, VALL-E può sintetizzare il suono di quella persona che dice qualsiasi cosa – e farlo in un modo che cerca di preservare il tono emotivo di chi parla.
I suoi creatori prevedono che VALL-E possa essere utilizzato per applicazioni di sintesi vocale di alta qualità, editing vocale in cui una registrazione di una persona può essere modificata e alterata da una trascrizione di testo (facendogli dire qualcosa che non ha originariamente), e la creazione di contenuti audio se combinati con altri modelli di intelligenza artificiale come GPT-3.
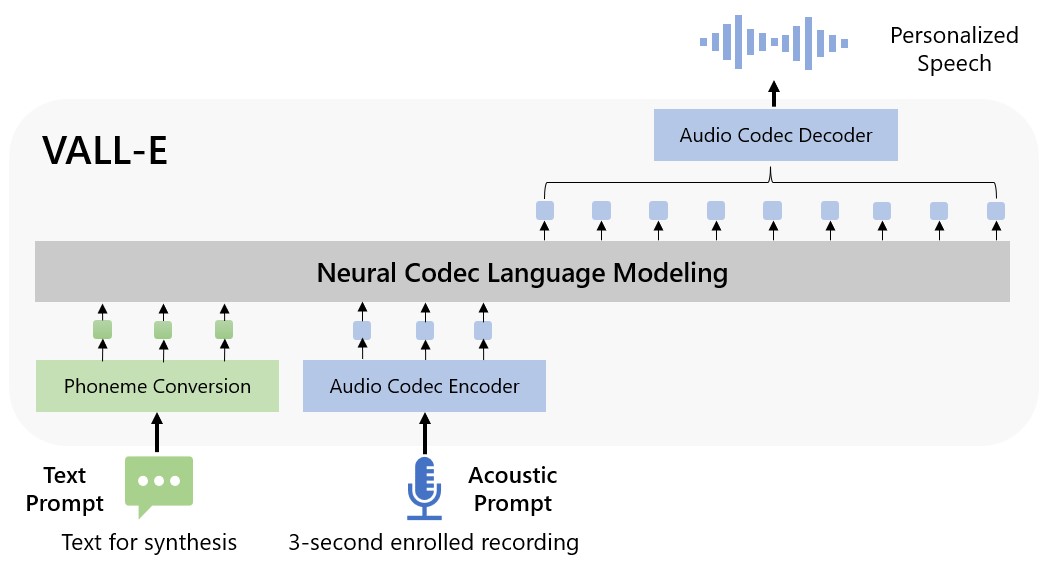
Microsoft definisce VALL-E un “paradigma del linguaggio di codifica neurale” ed è basato su una tecnologia chiamata EnCodec, dichiarato morto nell’ottobre 2022. A differenza di altri metodi di sintesi vocale che di solito sintetizzano il parlato elaborando forme d’onda, VALL-E genera codificatori fonetici separati da messaggi di testo e vocali. Fondamentalmente analizza come suona una persona, suddivide tali informazioni in componenti separati (chiamati “codici”) grazie a EnCodec e utilizza i dati di addestramento per abbinare ciò che “sa” su come suonerebbe quella persona se parlasse in altri frasi al di fuori del campione di tre secondi. O come dice Microsoft in a CARTA VALL-E:
Per il raggruppamento vocale personalizzato (ad es. TTS non ripreso), VALL-E genera i codici vocali corrispondenti modali ai codici vocali di registrazione di 3 secondi registrati e al messaggio vocale, che vincolano rispettivamente l’oratore e le informazioni sul contenuto. Infine, i codici audio generati vengono utilizzati per raggruppare la forma d’onda finale con il corrispondente decodificatore neurale.
Microsoft ha addestrato le capacità di sintesi vocale di VALL-E in una libreria di suoni, compilata da Meta, chiamata Libre Lite. Contiene 60.000 ore di lingua inglese da più di 7.000 parlanti, per lo più estratti da LibriVox Audiolibri di pubblico dominio. Affinché VALL-E ottenga un buon punteggio, il suono nel campione di tre secondi deve corrispondere a un suono nei dati di addestramento.
su val-e Esempio di sito webMicrosoft fornisce dozzine di esempi audio di un modello di intelligenza artificiale in azione. Tra i campioni, un “speaker prompt” è un suono di tre secondi fornito per VALL-E che deve essere imitato. Una “verità fondamentale” è una registrazione preesistente dello stesso oratore che pronuncia una particolare affermazione per scopi comparativi (una specie di “controllo” di un esperimento). “Baseline” è un esempio di sintesi fornito attraverso il tradizionale metodo di sintesi vocale e il campione “VALL-E” viene emesso dal modello VALL-E.
Microsoft
Durante l’utilizzo di VALL-E per generare questi risultati, i ricercatori hanno appena inserito un campione di “Speaker Prompt” di tre secondi e una stringa di testo (quello che volevano che la voce dicesse) in VALL-E. Quindi confronta il campione “Ground Truth” con il campione “VALL-E”. In alcuni casi, i due campioni sono molto vicini tra loro. Alcuni dei risultati VALL-E sembrano essere generati dal computer, ma è probabile che altri vengano scambiati per linguaggio umano, che è l’obiettivo del modello.
Oltre a preservare il timbro vocale e il tono emotivo di chi parla, VALL-E può anche simulare “l’ambiente acustico” di un campione vocale. Ad esempio, se il campione provenisse da una telefonata, l’uscita audio simulerebbe le caratteristiche acustiche e di frequenza di una telefonata nella sua uscita sintetizzata (è un modo elegante per dire che suonerebbe anche come una telefonata). e Microsoft campioni (nella sezione “Sintesi della diversità”) ha mostrato che VALL-E può generare variazioni di tono modificando i semi casuali utilizzati nel processo di generazione.
Forse a causa della capacità di VALL-E di alimentare malizia e inganno, Microsoft non ha fornito il codice VALL-E affinché altri possano provarlo, quindi non siamo stati in grado di testare le capacità di VALL-E. I ricercatori sembrano consapevoli del potenziale danno sociale che questa tecnologia potrebbe causare. Per concludere il documento, hanno scritto:
“Poiché VALL-E è in grado di sintetizzare un parlato che preserva l’identità di chi parla, potrebbe presentare potenziali rischi nell’uso improprio del modello, come lo spoofing del riconoscimento vocale o l’impersonificazione di un oratore specifico. Per mitigare questi rischi, è possibile costruire un modello di rilevamento per discriminare se un altoparlante specifico è stato sintetizzato o meno. Colonna sonora di VALL-E. Metteremo anche Principi Microsoft di Intelligenza Artificiale In pratica durante lo sviluppo di modelli.





